Open source is one of the best things to ever happen to software development.
It is also one of the easiest ways to accidentally ship legal obligations you did not sign up for.
Most teams know they rely heavily on open-source dependencies. Fewer teams know exactly what licenses those dependencies use, what obligations come with them, or how those licenses travel through transitive dependencies and container images.
That gap is what we call open-source license risk.
What is open-source license risk?
Every open-source package comes with a license. That license defines what you are allowed to do with the code and what you must do in return.
License risk appears when those obligations conflict with how you build, ship, or monetize your software.
Some common examples:
- Copyleft licenses can require you to share source code under certain conditions
- Attribution requirements mean you must include license text or copyright notices in your distribution
- Restricted-use licenses may prohibit commercial use or impose unusual conditions
- Policy violations occur when a dependency uses a license your company does not allow
None of this means open source is dangerous. It just means licenses are rules, and rules still apply even when the code is free.
Common Open-Source Licenses and Their Key Risks
Why this keeps catching teams off guard
Most license problems are not caused by bad decisions. They happen because modern software is deep, layered, and fast-moving.
A few reasons license risk is easy to miss:
1. Transitive dependencies pile up fast
You add one package. That package adds ten more. Those add fifty more.
Somewhere down the tree, a dependency introduces a license your team would never choose directly. You still ship it.
2. License metadata is messy
Package registries are not perfect. Licenses can be missing, mislabeled, or overly broad. Some packages list multiple licenses. Some change licenses between versions.
Relying on a single metadata field is often not enough.
3. Containers bring their own surprises
Your source repository may be clean, but your container image includes system packages, language runtimes, and build tools.
Those come with licenses too.
4. Audits do not care about intent
Customers, partners, and procurement teams increasingly ask for SBOMs and license disclosures. “We did not realize it was there” is not a satisfying answer during an audit.
What good license hygiene actually looks like
You do not need a law degree or a six-month process to manage license risk. Teams that do this well usually follow a few simple principles.
Define a clear license policy
Decide which licenses are allowed, which require review, and which are blocked.
Scan continuously, not once a year
License checks work best when they run automatically as part of your normal workflow. Pull requests, CI, and release pipelines are ideal places to surface issues early.
Fixing a license problem before a dependency ships is dramatically easier than fixing it after customers are involved.
Prioritize real risk
Not every license finding deserves the same level of attention. A scanner that treats everything as critical quickly becomes background noise.
You want the riskiest licenses to stand out so teams can act quickly and confidently.
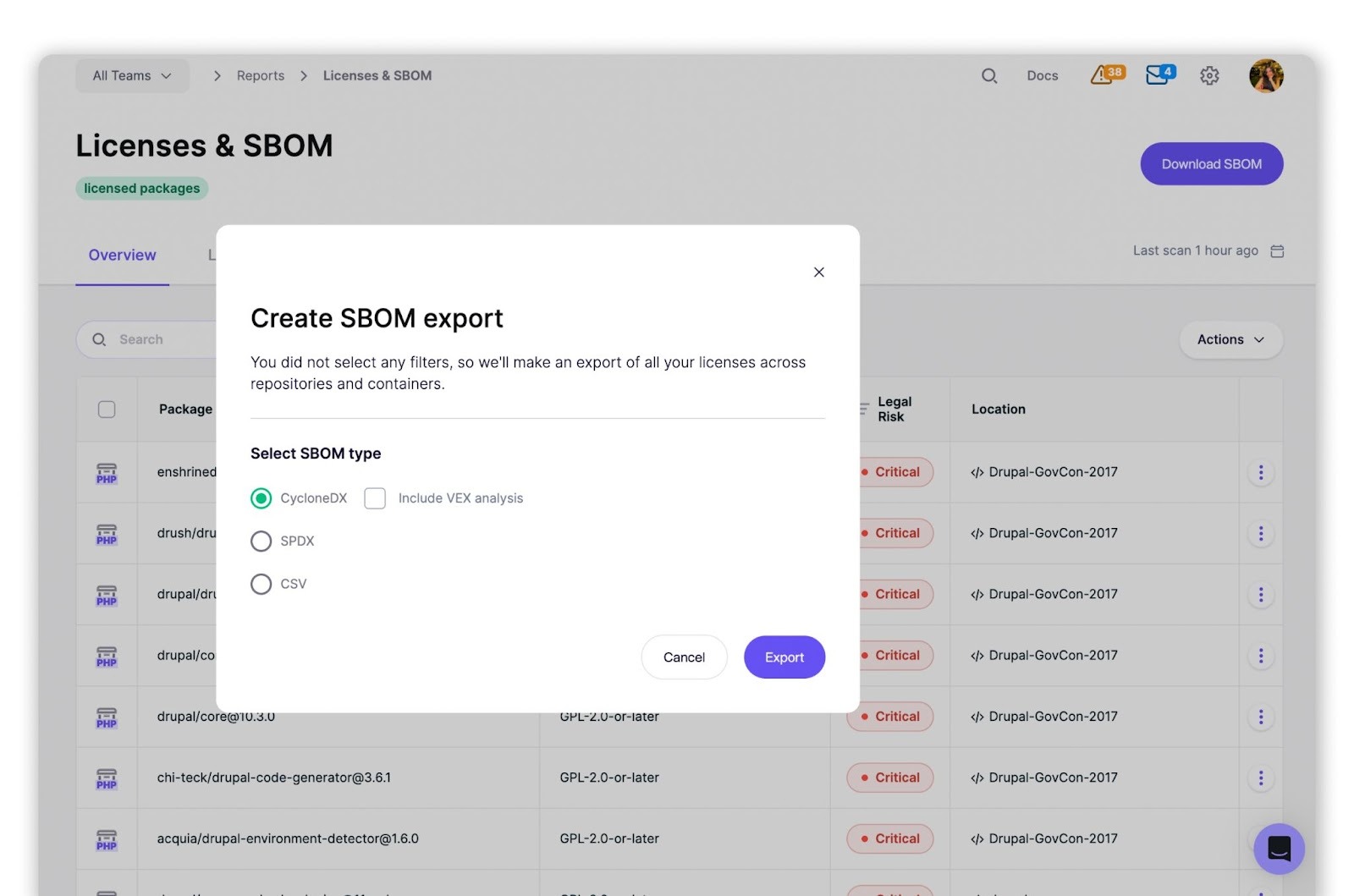
Generate audit-ready outputs
At some point, someone will ask for an SBOM or a license report. When that happens, you want to click “export,” not start a spreadsheet adventure.
License enforcement in practice
License enforcement works best when it runs where developers already work.
In practice, that means license checks happen automatically during pull requests and CI runs, not as a separate audit process. When a dependency introduces a license that violates policy, teams can choose how to respond: block the change, flag it for review, or simply monitor it.
Surfacing license issues before code is merged keeps enforcement predictable and prevents last-minute surprises during releases or audits.
How Aikido determines license risk (and why it’s reliable)
Aikido uses a layered approach to license detection that prioritizes accuracy, low noise, and audit readiness.
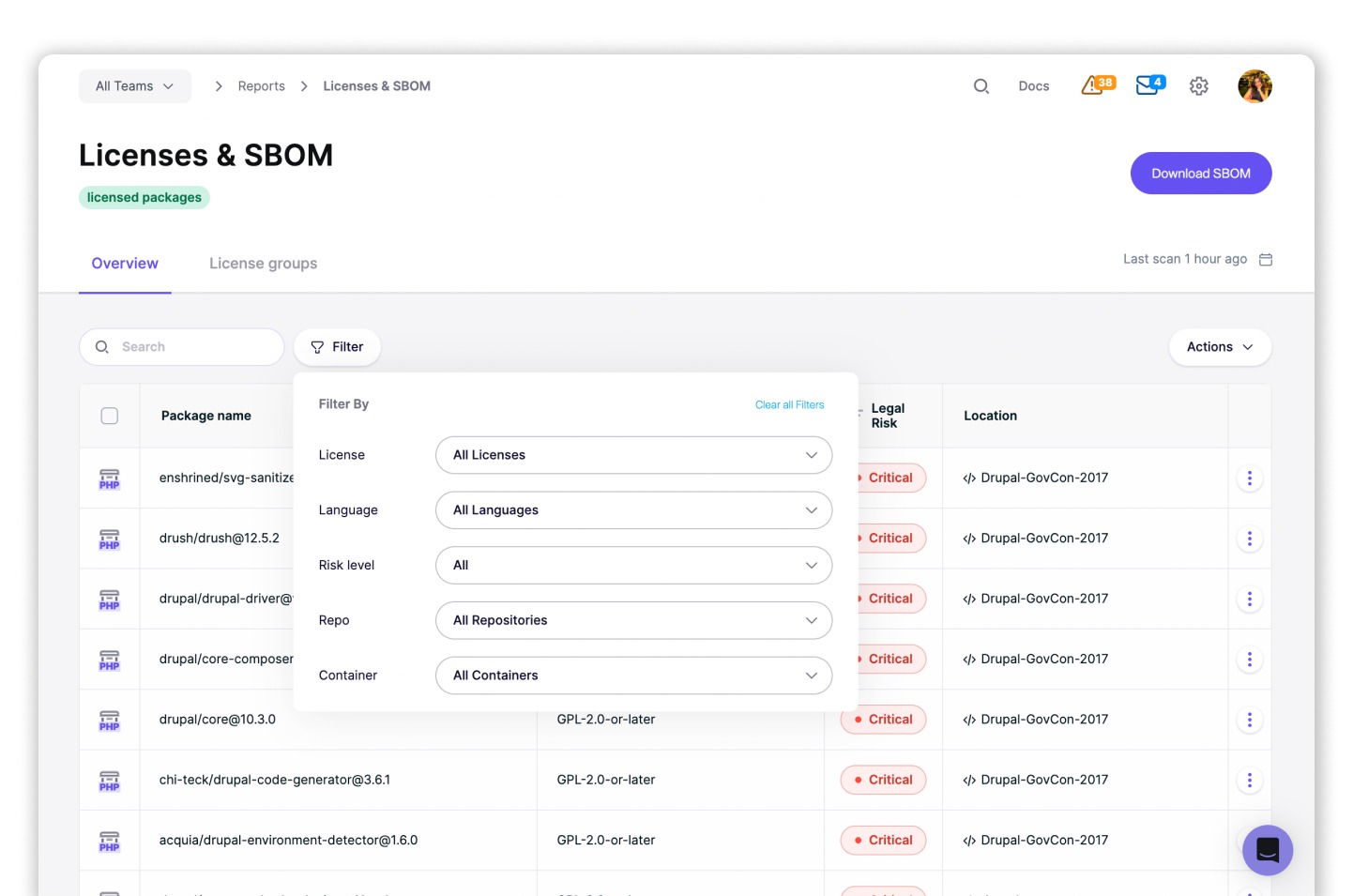
Many license scanners produce large numbers of false positives by relying on static pattern matching or incomplete metadata. Over time, this erodes trust in the results and causes teams to ignore license findings altogether.
Aikido doesn’t rely on a single “license” field from a package registry. In real-world dependency trees, that metadata is often missing, inconsistent, or misleading.
Instead, we use a layered process designed to be both accurate and audit-friendly:
1) We build a complete dependency and license graph
We ingest manifests and lockfiles across multiple ecosystems and normalize them into a dependency graph. Each dependency is enriched with registry and repository metadata so you get a reliable inventory of what you’re actually shipping, including transitive dependencies and OS packages in container images.
2) Rules first for the common cases
For the “boring 80%” of packages with standard licenses (MIT, Apache-2.0, BSD, etc.), Aikido uses deterministic detection rules. This is fast, consistent, and avoids unnecessary noise.

3) AI analysis for ambiguous or messy cases
When licenses are unclear (custom terms, unusual formatting, missing metadata, or multiple license files), Aikido applies AI-based analysis to interpret what’s present in the package and identify obligations that static tools often miss.
To handle large or non-standard license texts, we slice license files into relevant sections so the model can focus on the parts that matter (copyleft clauses, redistribution requirements, restricted-use terms, etc.).
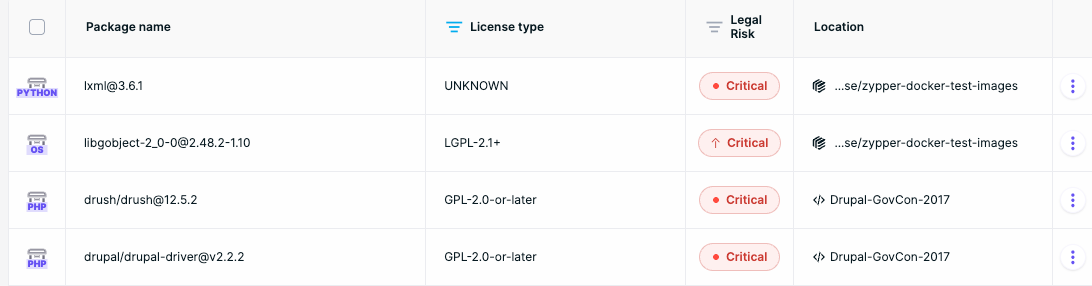
4) Human legal validation for high-impact edge cases
Aikido includes a validation step where ambiguous or high-impact findings can be reviewed by legal experts. This ensures that the final classification reflects real-world license obligations, not just best-effort automation.
5) Version-specific results and policy enforcement
License obligations can change between versions. Aikido resolves licenses for the exact dependency versions you ship and connects that data to policy controls, so teams can enforce “allow / review / block” rules directly in CI/CD.
How Aikido Compares to Other Tools
Aikido uses a hybrid approach that combines rules, AI-based analysis, and legal validation. This results in lower false positives and better handling of custom or proprietary licenses than tools that rely primarily on static pattern matching.
Unlike tools that focus solely on license text, Aikido also detects malware and pre-CVE risks, providing a more complete view of software supply chain risk. Ecosystem coverage extends beyond application dependencies to include operating system packages in container images.
Socket focuses primarily on JavaScript ecosystems and static license detection, which often leads to higher false-positive rates and brittle version handling. JFrog Curation provides broader ecosystem support but offers more limited handling of custom licenses and non-CVE risks.
License enforcement does not exist in isolation. Real-world supply chain risk includes malware, compromised packages, and emerging threats that are not yet assigned CVEs. Aikido was designed to address license risk as part of that broader picture.
Final thoughts
Open-source licenses are not something to fear, but they are something to respect.
With the scale of modern dependency trees, manual tracking does not work. The teams that stay ahead of license risk do three things well. They automate visibility, prioritize real issues, and integrate checks early in development.
That is exactly what we built Aikido to do.
If you want to see how license scanning fits into your existing workflows, you can try it out or generate your first SBOM in minutes. Your future self, and probably your legal team, will thank you.


