The International AI Safety Report 2026 is one of the most comprehensive overviews to date of the risks posed by general-purpose AI systems. It’s compiled by over 100 independent experts from more than 30 countries, and shows that while AI systems are performing at levels that seemed like science fiction only a few years ago, the risks of misuse, malfunction, and systematic and cross-border harms are clear.
It makes a compelling case for better evaluation, transparency, and guardrails. But one direct question remains under-explored: what does “safe” look like when AI operates autonomously against real systems?
A summary of the interesting takeaways from the International AI Safety Report includes:
- At least 700 million people use AI systems weekly, with adoption rates faster than the personal computer in its early years
- Several AI companies released their 2025 models with additional safety measures after pre-deployment testing failed to rule out that the systems could help non-experts develop biological weapons. (!!!) (Unclear if the additional safety measure would still prevent it entirely)
- Security teams have documented AI tools being used in actual cyberattacks by both independent actors and state-sponsored groups.
The report talks at length about the approaches to manage many of the risks associated with AI– here’s our take:
Where Aikido agrees with the report (and ways it could go further)
1. Layered defense matters
The report outlines a defense-in-depth approach to AI safety, breaking it into three layers: building safer models during training, adding controls at deployment, and monitoring systems after they're live. We agree broadly with the application of these layers.
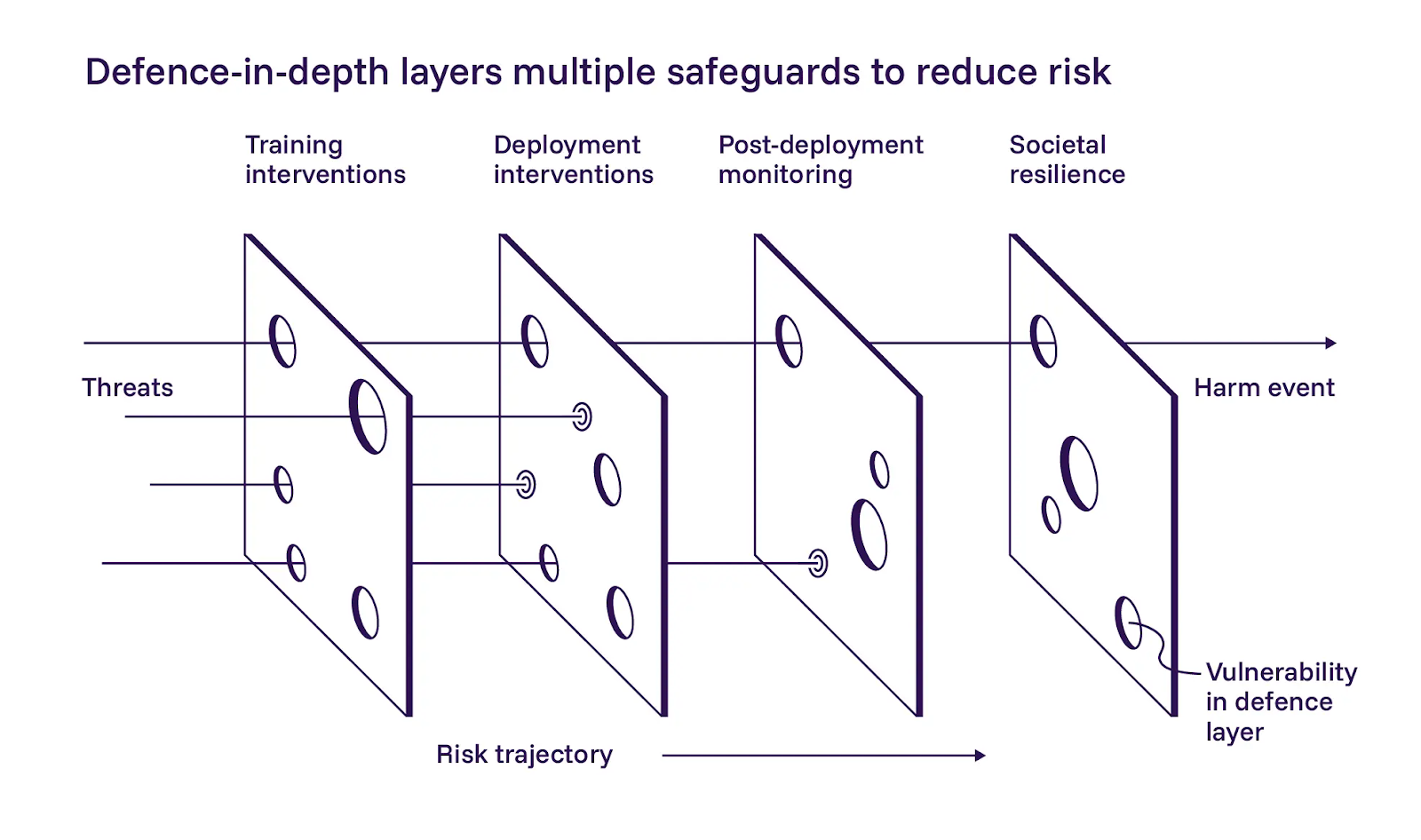
The report emphasizes the first layer, the safer model development. They’re cautiously optimistic that training-based mitigations can help, but also acknowledge that they are hard to implement at scale. While we agree that AI operators should give their best effort during training, our philosophy diverges slightly from the report in this case. We can’t rely on prompts or instructions to keep agentic systems in scope. Layered defense only works if each layer can fail independently.
2. Validation as a Safety Requirement
The report stays light on implementation details for the second layer, deployment-time controls, but we think this is where the most immediate progress can happen.
The International Report documents models gaming their evaluations in concerning ways. Some find shortcuts that score well on tests without actually solving the underlying problem (reward hacking). Others intentionally underperform when they detect they're being evaluated, attempting to avoid restrictions that high scores might trigger (sandbagging). In both cases, the models optimize for something other than the intended goal.
We reached the same conclusion: once AI systems operate autonomously, you can't trust what they self-report, their confidence levels, or their reasoning traces. An agent that validates its own discoveries creates a single point of failure disguised as redundancy. Safe operation requires treating initial findings as hypotheses, reproducing behavior before reporting, and using validation logic that is separate from discovery. This validation can even come from another AI agent.
3. Reduce risk before allowing agents to run in live environments
The report's third layer covers observability, emergency controls, and continuous monitoring after systems go live. This aligns with what we’ve seen in our operations.
Black box operation isn't acceptable for autonomous systems that interact with production infrastructure, so we treat emergency stop mechanisms as non-negotiable requirements. If you can't see what an agent is doing or stop it when it’s off the rails, you're not operating it safely, regardless of how good the underlying model is.
4. Prompt Injection Requires Enforced Constraints, Not Hope
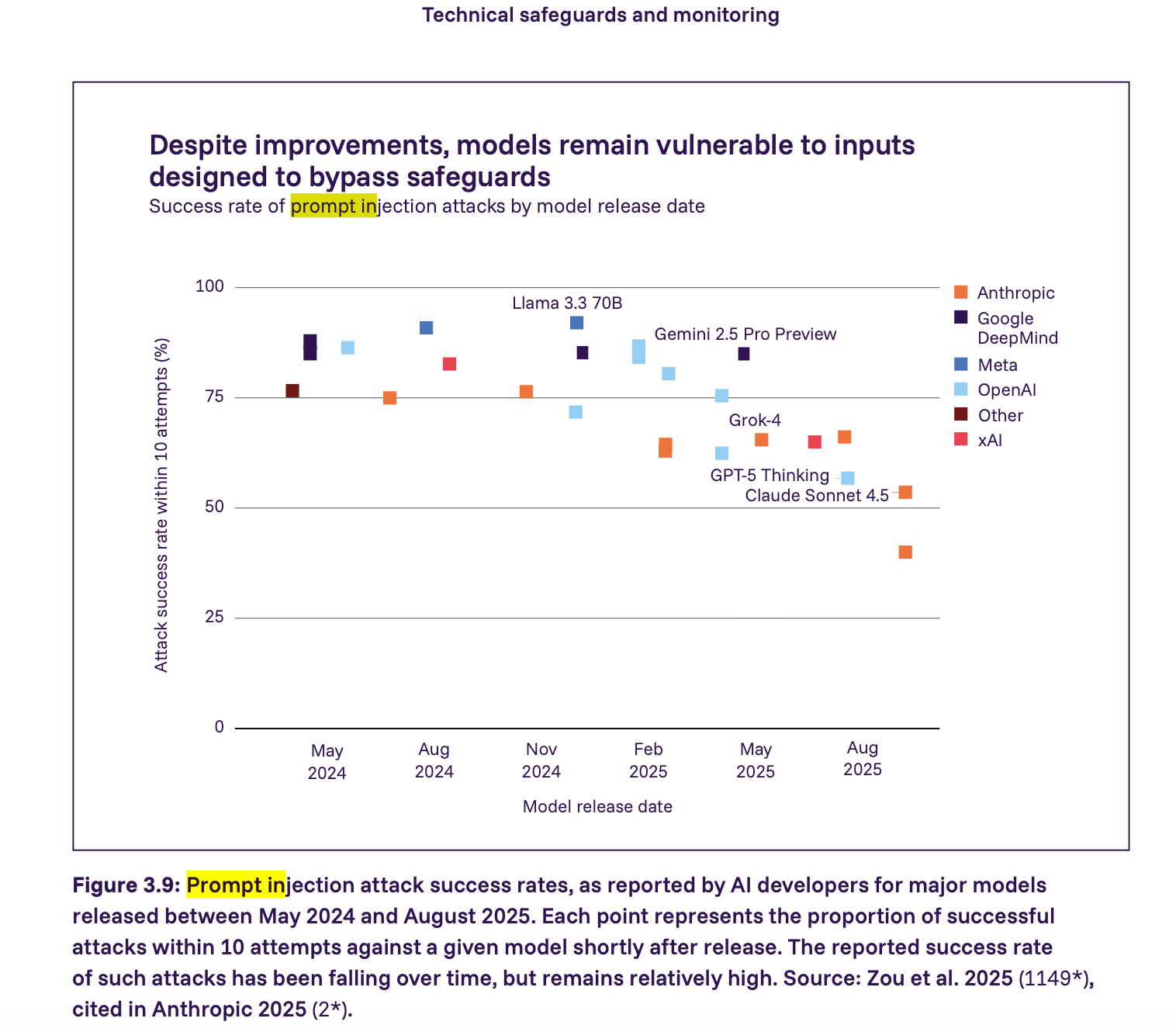
The report shows that prompt injection attacks are still a serious vulnerability– many major models in 2025 could be successfully attacked by prompt injection with relatively few attempts. The success rate is falling but remains relatively high. We go a step further than the report and maintain that any agent interacting with untrusted application content must be assumed vulnerable to prompt injection by default. Safety, in this context, comes from enforcing constraints and not hoping models behave correctly.
What We Think Should Come Next
Systems, Not Just Models
The report makes a strong case for defense-in-depth, transparency, and evaluation. These matter, but many of the most immediate problems occur once models connect to tools, credentials, and live environments. This is why implementation-level requirements are so important (and necessary). We have to translate these principles into concrete technical requirements that teams can implement.
Based on operating AI pentesting systems in production, we believe the minimum safety requirements for autonomous AI systems should include:
- Abuse prevention and ownership validation
- Enforced scope control at the network level
- Isolation between reasoning and execution
- Full observability and emergency controls
- Data residency and processing guarantees
- Prompt injection containment
- Validation and false positive control
We found that these are the minimum enforceable requirements for safety. If you omit any one of them, you introduce unacceptable risk into the system. We go more into these requirements in our blog post on AI Pentesting Safety.
Safety Baselines as Policy Building Blocks
The International AI Safety Report represents significant progress toward a shared understanding of AI risks across governments, researchers, and industry. The challenge now is bridging research findings, regulatory frameworks, and real-world deployment practices.
The report does bring up some genuinely high-stakes scenarios and unsettling stats about how quickly capabilities are advancing. That said, this isn’t a reason to panic or regulate “AI” as a scary monolith. The report itself notes that safeguards vary widely across developers and
that prescriptive mandates can stifle defensive innovation. We agree. Regulation should avoid mandating a single implementation path. Instead, policies should define clear, outcome-oriented safety baselines that can be building blocks for broader frameworks.
As part of the movement toward creating more outcome-focused safety frameworks, we've published our document on the Minimum Safety Requirements for AI-driven Security Testing. For teams evaluating AI pentesting tools or building autonomous security systems, this guide serves as a vendor-neutral reference. We hope this helps teams evaluate AI pentesting tools, build safer autonomous security systems, and contribute to establishing clear baselines that work for both builders and regulators.


